Google CloudでOCR!Document AIとGoogle Cloud Vision APIを触ってみた

先日、猫が右腕に乗り4.5kgの負荷をかけたままゲームをやり続けました。
右腕だけがムキムキになった気がします。

▲ こんな可愛い感じなら良かったんだけど
こんにちは。データアナリティクス事業本部 インテグレーション部 機械学習チームのShirotaです。
この記事は、ブログリレー『Google CloudのAI/MLとかなんとか』の8本目の記事になります。
今回は、Google CloudでOCR(光学式文字認識)を行えるサービスのうち『Document AI』と『Cloud Vision』を中心に触ってみたのでまとめてみようと思います。
Google Cloudで利用できるOCRについて
まずは簡単にOCRについて説明します。
OCRは「Optical Character Recognition/Reader」の略で、画像や物理媒体のドキュメントをカメラやスキャナを用いて画像データとして取り込み、そこに存在する文書や単語をコンピュータで認識可能なテキストデータに変換する技術のことを指します。
AIが関わっていないOCRそのものは1950年代には商用システムとして利用され始め、日本でも1960年代後半には郵便区分機の中で郵便番号の識別のために利用されていました。
今でも郵便物には人間の目に見えないバーコードが印字されこれを元に郵便物の区分がなされていますが、これはOCRで認識した情報をより読み取りが早いバーコードに変換して印字したものなのです。
そんなOCRですが、手書き文字やフリースペースへの記述などのブレが大きいデータの認識が苦手という短所がありました。
また、英語と異なる日本語の以下のような特徴がOCRの精度に影響しがちでした。
- 文章の区切りが分かりづらい
- 英語は単語ごとにスペースで分かれるが、日本語にはそれがない
- 縦書きと横書きが存在する
- 単語の種類が多い
- 英語がアルファベット26種類なのに対して、日本語はひらがなカタカナだけで100種類、それに漢字を加えると常用漢字だけでも2,136種類(2023年12月現在)の文字がある
そこで、ディープラーニングを組み合わせ文字認識の精度を高めたAI-OCRという分野が生まれました。
Google Cloudで利用できるOCR系のサービスはこのAI-OCRを利用したものになっています。
事前学習済みのモデルをGoogle Cloudが用意してくれていて、それぞれAPIの提供もされているサービスとして以下の二つがあります。
- Document AI
- Cloud Vision
またVertex AIでカスタム学習モデルをトレーニングしてエンドポイントを用意することもできます。
OCRができるマネージドサービスが複数あったので、ちょっと変則的にはなりますがそれぞれを簡単に触った上で特徴や使い分けについてをまとめていこうと思います。
とりあえず触ってみた
各種APIの有効化といった基本的な準備については以下ブログの手順を参考にしてください。
それぞれのAPI有効化を行えるページは以下にリンクとして貼っておきます。
Google Cloudアカウントにログインしている場合、自分が開いているプロジェクトのAPI有効化ページに遷移します。
Document AI
Cloud Vision API
OCRを試したデータ
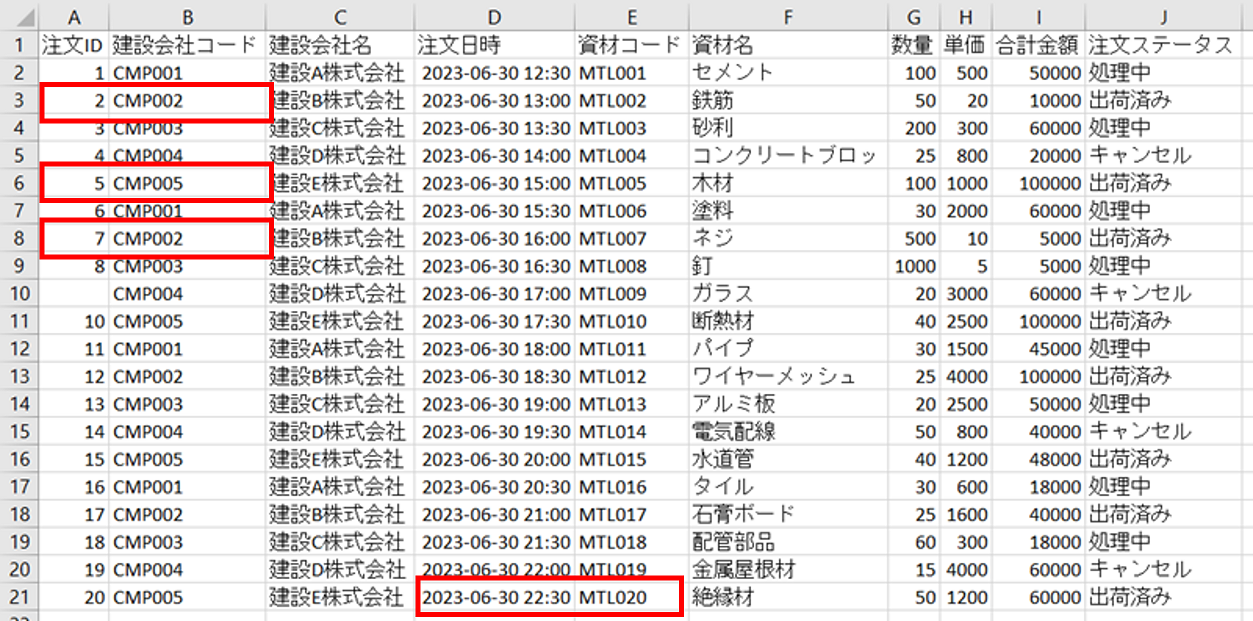
以下二つのデータを試してみました。

▲ 病院でもらった領収証、PNG形式

▲ 海外のネイルポリッシュを購入した時の納品書、JPEG形式
実際に試してみる
Document AI
Document AIのコンソールから今回はAPIを叩いてみます。
Document AIはそれぞれ実行した分析ごとにプロセッサを作成する必要があります。
OCRを利用する場合は、以下の「Document OCR」プロセッサを作成します。

▲ 現状ではEUリージョンとUSリージョンでのみ作成が可能です
今回はUSリージョンでプロセッサを作成しました。
マイプロセッサから先程作成したプロセッサを選択し、OCRを実行したい画像をアップロードします。

▲ 計画性がなく、プロセッサ名に「japanese」と入れてしまいました
すると1分程度で画像のOCR分析が実行されました。

▲ 半角の潰れ気味の「インフルエンザ」がちゃんと読み取れていた
左側の縦書きの「私費分・その他」も正しく読み取れており、右下の印鑑も「領収印」と被っていない一文字目は正しく読み取れていました。
ただ、印鑑と被ってしまった「領収印」は「領取印」と間違われてしまったりスペース間隔の大きい縦書きの文字などは一文字ずつ認識されてしまったりしていました。
次に、英語の納品書も同様にOCR分析してみました。

▲ 個人的にすごいなと思ったところ
円形に並べられた文字も認識できるところは認識できていたのと、判子で押された文字列も正しく認識されていたところがすごいなと思いました。
ただ、印刷であっても文字が潰れているところは難しかったのか、メールアドレスの「ilnp」のiとlがほぼくっついてしまっている箇所は片方の文字が読み取れていないという結果になりました。
Cloud Vision API
次に、Cloud Vision APIでOCRを試してみました。
上記の2ファイルをCloud Storageに置き、Cloud Shellから以下コマンドを実行します。
gcloud ml vision detect-document gs://OCR処理したいファイルのファイルパス > ./output.json
今回出力されるのはJSON形式で出力され、相当な行数あったため出力結果はファイルにエクスポートしました。

▲ Cloud Shellに出力したコマンド出力結果のjsonファイルはここからダウンロードできる
出力結果は相当な長さがあったので省略しますが、構造についてざっくり説明すると以下のようになっていました。
{
"responses": [
{
"fullTextAnnotation": {
"pages": [
{
...
}
],
"text": "ここにOCRで読み取った文章が入る"
},
"textAnnotations": [
...
]
}
]
}
"textAnnotations"の"description"にも上記の"text"と同じくOCRで読み取った文章が入っていました。
公式ドキュメントの記載によると、PDFやTIFFファイルにOCRを実施した場合には"fullTextAnnotation"のみがレスポンスに返ってくるようでした。
上記ドキュメントに記載があるように、レスポンスの階層は - TextAnnotationPage - Block - Paragraph - Word - Symbol
となっており、Symbolの中には - boundingBox - vertices - confidence - property(任意) - languageCodeなど複数のパラメータがある模様 - text
といった、その文字の内容やバウンディングボックスの座標や信頼度などが入っていました。
OCRしてみた結果としては、以下のような結果が得られました。
- Vision AIでうまくいかなかった潰れた文字や印鑑が被った文字は同様の間違った解析をされていた
- 「領収証」が「領取証」になっていた
- 「収」と「取」は漢字の作りが似ているから?
- Googleで検索すると一定数同様の漢字変換がされた文章がヒットする
- 一応「領取」という単語は存在しそう
触ってみて考えたこと
実際にOCRを試してみたこととドキュメントをそれぞれ読んでみて、Document AIとCloud Vision APIの立ち位置などについて考えてみました。
Document AI
- ドキュメント処理に最適化されている
- ドキュメントデータから非構造化データを取得できる
- ブロックや段落の対応があり、キーバリューのペアの識別のみならずテーブルデータの構造も取得できるので構造化データの識別も多少はできそう
- これは主にFormPaserプロセッサでできる
- ドキュメントからテキストとレイアウト情報を抽出したかったらDocument OCRプロセッサ
- サポートしているファイルタイプは以下
- PDF,TIFF,GIF,JPEG,PNG,BMP,WEBP
Cloud Vision API
- OCR機能がある画像検出サービス
- 基本的にはテキストを含むオブジェクトを画像や動画から検出する時に使う
- サポートしているファイルタイプは以下
- JPEG,PNG8,PNG24,GIF,アニメーション GIF(最初のフレームのみ),BMP,WEBP,RAW,ICO,PDF,TIFF
- メインは画像検出サービスであり(顔認識やランドマーク認識など)、OCRの機能だけができるサービスではない
実際にアウトプットの精度や目的に合わせたデータの取り出し・加工が可能かといった観点で触っていき、やりたいことを実現する実装ができるかを検証していく必要はあるなと感じました。
個人的には、日本語の読み取り精度や判子の文字のような手書き文字に近しいタイプの文字も読み取れていたことに驚かされました。
このブログが、Google CloudのOCRを手軽に試してみたい人に届けば幸いです。